※このページは、自動車関連企業等より配信されたパブリシティリリース記事をそのまま転載しております。掲載内容に関するお問い合わせ等につきましては、直接リリース配信元までお願いいたします。
〜日本語で対話可能な画像-言語複合モデルを実現〜
完全自動運転車両の開発・販売に取り組むTuring株式会社(千葉県柏市、代表取締役:山本 一成、以下「チューリング」)は、日本語を含む複数言語対応の大規模マルチモーダル学習ライブラリ「Heron(ヘロン)」と、それにより学習した最大700億パラメータのモデル群を公開したことをお知らせします。
チューリングでは高度な自動運転を実現するため、視覚情報によって得られた情報を、人間のように言語化して高度な文脈を理解できるAIモデルを開発しています。今回公開したマルチモーダルモデルの学習技術と知見を活かし、完全自動運転にむけた開発を進めてまいります。

- マルチモーダルについて
近年注目されている大規模言語モデル(LLM)は、大量のテキストデータを学習に用いることで、広範な知識の獲得や人間のような応答が可能になります。大規模言語モデルは、一般的にその入力と出力はテキストに限定されるため、画像など視覚情報を用いたタスクには直接適用できないという課題があります。
例えば、「洗面台に横たわる猫」の写真に対し、「この画像の面白い点は何ですか?」という質問に答えるためには、画像と言語の双方を入力情報として扱えなければなりません。このように、入力の形態(モーダル)が複数あることを「マルチモーダル」と呼びます。
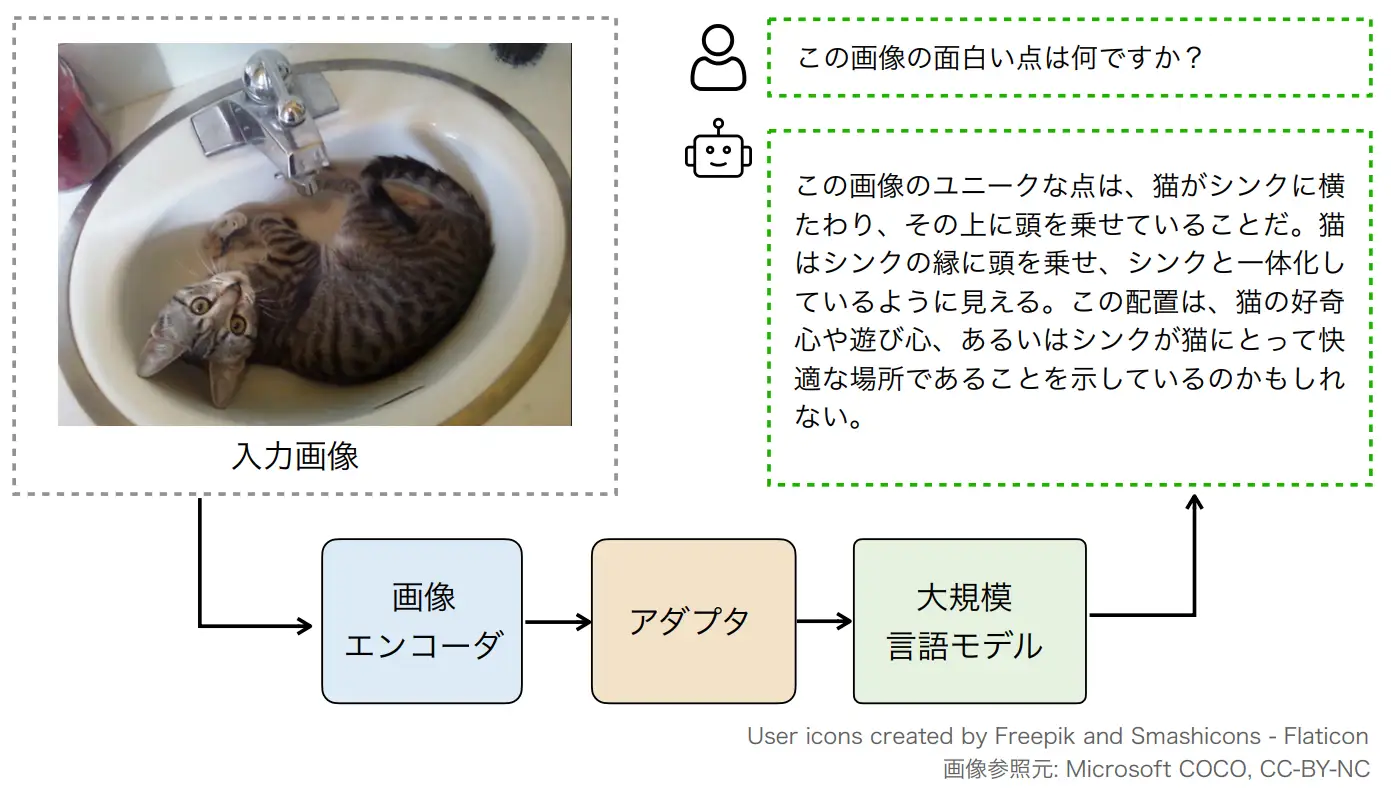
今回公開したマルチモーダルモデルは、画像認識用に事前学習された「画像エンコーダ」部分と「大規模言語モデル」部分、およびその間をつなぐ「アダプタ」部分から構成されます。橋渡しするアダプタ部分を学習した後、画像エンコーダおよび大規模言語モデルも追加学習することで、全体として画像に何が写っているかを正確に把握しつつ、豊富な言語モデルの知識を利用して回答することが可能になります。
- マルチモーダル学習ライブラリ「Heron」について
チューリングが開発したマルチモーダル学習ライブラリ「Heron」(読み: ヘロン、アオサギの英名)は、画像認識モデルと大規模言語モデルを接続し、各モジュールを追加学習するための学習コード、日本語を含むデータセット、および学習済みのモデル群から構成されます。
Heronのモデル学習の最大の特長は、対話を含むデータセットを用いることにより、自然かつ適切な対話が可能となっている点です。これまでのマルチモーダルモデルでは単純な回答しかできなかった複合的な画像-言語タスクにおいて、より詳細で自然な文章生成が可能となり、前の質問を含む文脈を理解して応答することができます。
学習用ライブラリは、学習する大規模言語モデルを自由に変換可能であり、既存の言語モデルの性能を活かしつつ、今後開発・公開される新たな大規模言語モデルに対しても容易に対応できる柔軟性を有しています。本格的にマルチモーダルモデルを学習するために系統的に学習できるように工夫されており、ソースコード部分については研究・商用利用が可能なApache License 2.0で公開しました。
今回公開した学習済みのマルチモーダルモデル群は、Llama 2-chat、ELYZA-Llama 2、 Japanese StableLMなどをベースにHeronで追加学習を行い、マルチモーダル化させたものです。
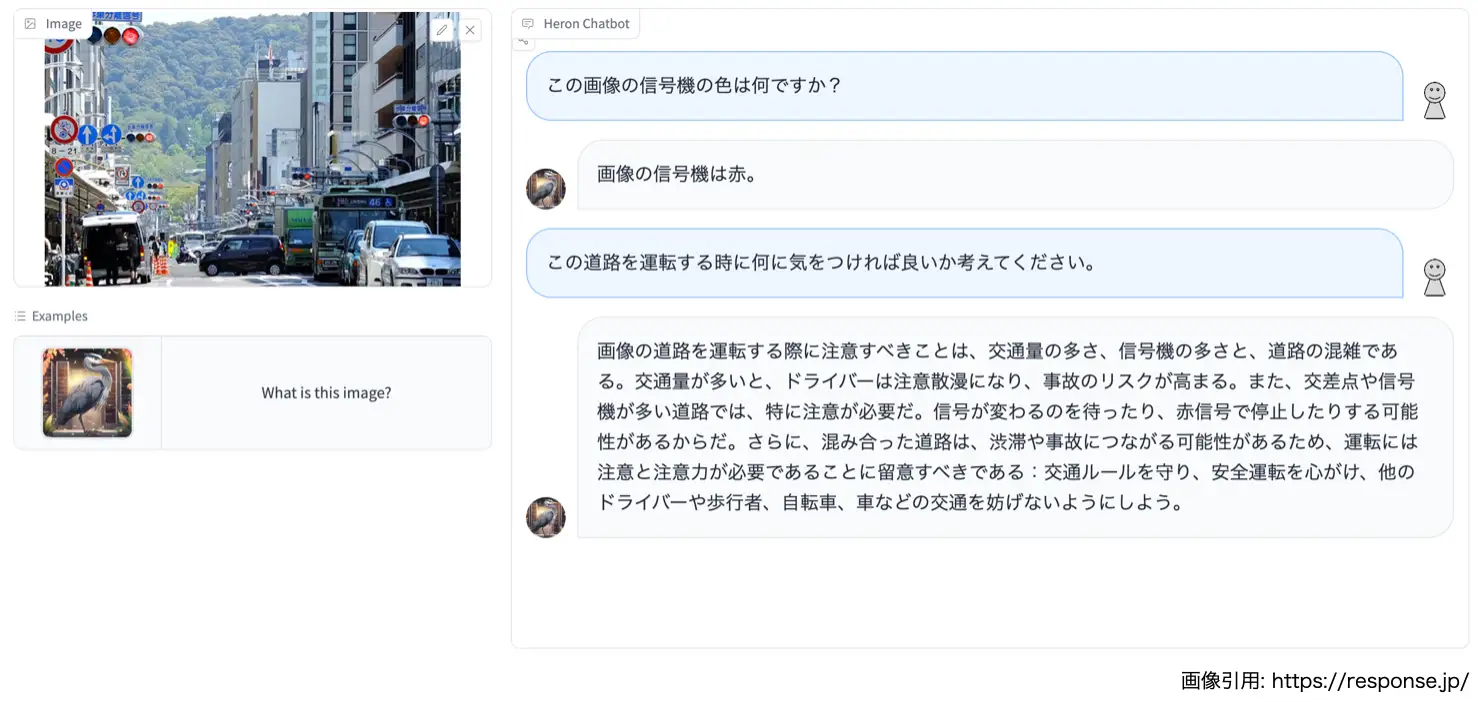
こちらの学習したモデルをWebブラウザ上で試すことができるデモページもあわせて公開しました。
https://huggingface.co/spaces/turing-motors/heron_chat_blip
さらに、注釈テキストやQ&Aからなる約15万枚の画像/テキストの英文データセットに対し、独自に日本語に翻訳した大規模な日本語の画像/テキスト情報のデータセットを作成・公開しました。このような対話形式のマルチモーダル学習向けの大規模な日本語データセットの公開は、世界で初めてとなります。
【学習用ライブラリの公開URL】
https://github.com/turingmotors/heron
【マルチモーダルモデル群の公開URL】
https://huggingface.co/turing-motors
【学習用データセットの公開URL】
https://huggingface.co/datasets/turing-motors/LLaVA-Instruct-150K-JA
- LLMと完全自動運転の関係性
近年、AI技術の進化に伴い、大規模言語モデル(LLM)が注目を集めています。LLMは、大量のテキストデータから学習し、人間のような自然な文章を生成したり、質問に答えたりすることができるAIモデルです。チューリングは、完全自動運転の実現には人間と同等以上にこの世界を理解した自動運転AIが必要であると考え、言語を通じて極めて高いレベルでこの世界を認知・理解している、LLMを含むマルチモーダルモデルの開発を進めています。
<参考リリース>
https://prtimes.jp/main/html/rd/p/000000024.000098132.html
https://prtimes.jp/main/html/rd/p/000000032.000098132.html
- チューリングについて
チューリングは、「We Overtake Tesla」をミッションにかかげ、完全⾃動運転EVの量産を⽬指すスタートアップです。世界で初めて名人を倒した将棋AI「Ponanza」の開発者である⼭本⼀成と、カーネギーメロン⼤学で自動運転を研究し、Ph.D.を取得した⻘⽊俊介によって2021年に共同創業され、AI深層学習技術を⽤いた限定領域に留まらない「完全自動運転」の実現を目指しています。

社名:Turing株式会社(読み:チューリング、英語表記:Turing Inc.)
代表者:代表取締役 ⼭本⼀成
設⽴:2021年8⽉
資本⾦:3,000万円(2022年9⽉末現在)
事業:完全自動運転EVの開発・製造
本社:千葉県柏市若柴226番地44中央141街区1
URL:https://www.turing-motors.com
- 採⽤情報
完全⾃動運転システム・EV⾞両を⼀緒につくる仲間を積極的に募集しています。
採⽤ページ:https://www.turing-motors.com/jobs
- 報道機関からのお問い合わせ先
広報担当(田中・山崎):pr@turing-motors.com
人気記事ランキング(全体)
なぜ消えた?排気温センサー激減のナゾ 排気温度センサーは、触媒の温度を検知し、触媒が異常な高温に達した際に排気温度警告灯を点灯させるための重要なセンサーである。とくに不完全燃焼などによって排気温度が上[…]

様々な用途に対応する、INNO ルーフギアケース720 SUVやピックアップトラックのルーフに積まれている細長いボックスは、ルーフボックスと呼ばれるカーアクセサリーの一種だ。なかでも、カーメイトが展開[…]

“華美にあらがう上質さ”という新しい価値観 キャンピングカーといえば、豪華な装飾や派手な装備を前面に押し出したモデルをイメージする人も多い。しかし今回紹介するモデルは、その真逆を行く存在だ。コンセプト[…]

簡単施工の超撥水性能でワイパー不要の『ゼロワイパー』を実現 カーメイトのゼロワイパーは、フロントガラスに雨が付かない超撥水ガラスコートで、すでに愛用している方も多いはず。 とにかくフロントガラスに水滴[…]

一見ナゾすぎる形状…でも“使い道を知った瞬間に評価が変わる” カーグッズを探していると、時折「これは一体何に使うのか」と戸惑うような形状のアイテムに出会うことがある。このドアステップもまさにその典型で[…]

最新の投稿記事(全体)
緩めるのではなく「破壊する」という発想 ナットの角がナメてしまった場合、工具がしっかり噛まなくなり、回すこと自体が困難になる。さらに、無理に回そうとすると状況が悪化し、完全に手がつけられなくなるケース[…]

意外と使い切れていない車内スペースの実情 クルマの中を見渡してみると、すでに何らかのカーグッズが設置されているケースは多い。特にスマートフォン関連のホルダーや充電器といったアイテムは、もはや必需品とい[…]

4A-GELU型直列4気筒DOHCエンジン カローラ+αの予算で買えた、ミッドシップならではの切れ味抜群の旋回性能 年々実質給与が下がり続ける情けない時代を生きる現代日本のサラリーマンには、20年間で[…]

1960〜70年代に登場した、マツダのロータリーエンジン搭載モデル マツダが初めてロータリーエンジンを搭載した車両を発売するのは、1960年代のこと。それ以降、ロータリーエンジン搭載車種を次々と市場に[…]

専用設計だから自然に馴染む。違和感のないフィット感 ルームミラーは、運転中に何度も視線を向ける装備であるため、見やすさや違和感のなさが非常に重要になる。純正ミラーでももちろん機能としては十分だが、視認[…]




